
Kann mir jemand sagen, warum D3DXSaveTextureToFile bzw. D3DXSaveTextureToFileInMemory so langsam sind?
Ich würde gerne 5 generierte 2048x2048 Texturen als D3DXIFF_DDS speichern... das schlägt aber mit gut 8 Sekunden zu buche... erst dachte ich eben, dass es vielleicht am speichern selbst liegt, aber da das D3DXSaveTextureToFileInMemory fast genauso lange braucht, frage ich mich doch, woran es liegt und was man da tun kann.
[DX9] D3DXSaveTextureToFile(InMemory) langsam
-
Schrompf

- Moderator
- Beiträge: 5402
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas
- Wohnort: Dresden
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Sind die Texturen mit der GPU generiert worden? Wenn ja, dann dauert das Zurückladen aus dem VideoRAM so lange.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Achja stimmt! Das könnte es natürlich sein. Dank dir!Schrompf hat geschrieben:Sind die Texturen mit der GPU generiert worden? Wenn ja, dann dauert das Zurückladen aus dem VideoRAM so lange.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
DMA ist doch nicht langsam. Hat mehrere GB/s.Schrompf hat geschrieben:Sind die Texturen mit der GPU generiert worden? Wenn ja, dann dauert das Zurückladen aus dem VideoRAM so lange.
https://memcp.org/ <-- coole MySQL-kompatible In-Memory-Datenbank
https://launix.de <-- kompetente Firma
In allen Posts ist das imo und das afaik inbegriffen.
https://launix.de <-- kompetente Firma
In allen Posts ist das imo und das afaik inbegriffen.
-
Schrompf
- Moderator
- Beiträge: 5402
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas
- Wohnort: Dresden
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Ja, aber jeder einzelne Zugriff verursacht ja schonmal einen Sync mit der GPU, also je nach Auslastung bis vielleicht 100ms. Und da hast Du noch nicht ein Byte übertragen. Den Rest kann ich nicht bewerten, da hängt dann viel von der Implementierung ab.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
-
Krishty

- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Verzeiht die Off-Topicity, aber:
Was bringt eine asynchrone GPU eigentlich? Ich meine: Mir ist durchaus klar, dass es ungünstig wäre, die CPU zwischen Zeichenbefehlen auf die GPU warten zu lassen. Aber wtf soll es bringen, die GPU 100 ms hinterherzeichnen zu lassen?! Was spricht dagegen, CPU und GPU am Ende jedes Einzelbilds zu synchronisieren?
Gruß, Ky
Was bringt eine asynchrone GPU eigentlich? Ich meine: Mir ist durchaus klar, dass es ungünstig wäre, die CPU zwischen Zeichenbefehlen auf die GPU warten zu lassen. Aber wtf soll es bringen, die GPU 100 ms hinterherzeichnen zu lassen?! Was spricht dagegen, CPU und GPU am Ende jedes Einzelbilds zu synchronisieren?
Gruß, Ky
-
Alexander Kornrumpf
- Moderator
- Beiträge: 2198
- Registriert: 25.02.2009, 13:37
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Ich kann das ja immer nur aus der CUDA Perspektive beurteilen und da lässt sich sagen:
1) antisteo: Bandbreite kann selbstverständlich ein Problem sein (was soll das mit den GB/s überhaupt für ein Argument sein? Man hat nie genug Hubraum). Abgesehen davon: flüchtiges googlen hat ergeben das DDR3 1600 Dual Channel 24GB/s über den FSB erreicht, PCIe 3.0 x16 erreicht 16GB/s. Das ist schon nen Unterschied den du merkst.
2) Krishty: Vielleicht habe ich dich da falsch verstanden, aber nachdem was NVIDIA in das Marketing von CUDA investiert hat halte ich es für extrem unwahrscheinlich dass sie ihre Prozessoren auf Basis eines so seltsamen Konzepts wie "Einzelbild" mit etwas so hoffnungslos langsamen wie einer CPU synchronisieren wollen.
1) antisteo: Bandbreite kann selbstverständlich ein Problem sein (was soll das mit den GB/s überhaupt für ein Argument sein? Man hat nie genug Hubraum). Abgesehen davon: flüchtiges googlen hat ergeben das DDR3 1600 Dual Channel 24GB/s über den FSB erreicht, PCIe 3.0 x16 erreicht 16GB/s. Das ist schon nen Unterschied den du merkst.
2) Krishty: Vielleicht habe ich dich da falsch verstanden, aber nachdem was NVIDIA in das Marketing von CUDA investiert hat halte ich es für extrem unwahrscheinlich dass sie ihre Prozessoren auf Basis eines so seltsamen Konzepts wie "Einzelbild" mit etwas so hoffnungslos langsamen wie einer CPU synchronisieren wollen.

Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Entschuldigt bitte das lange Zitat:
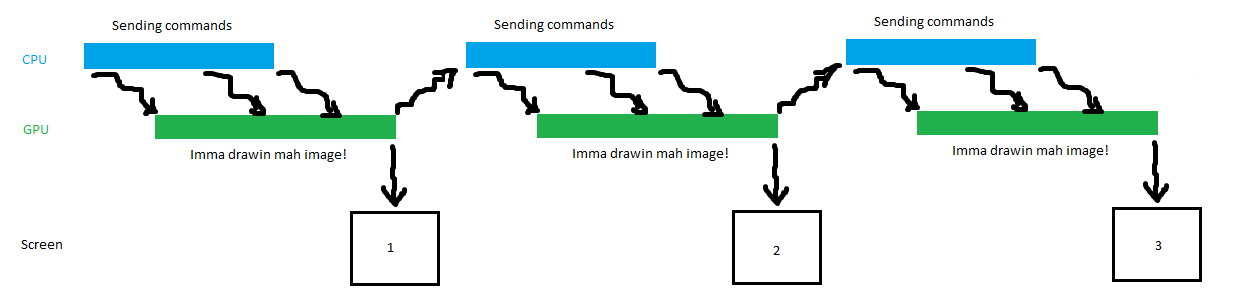
Mit kompletter CPU-GPU-Synchronisierung:
Asynchron:
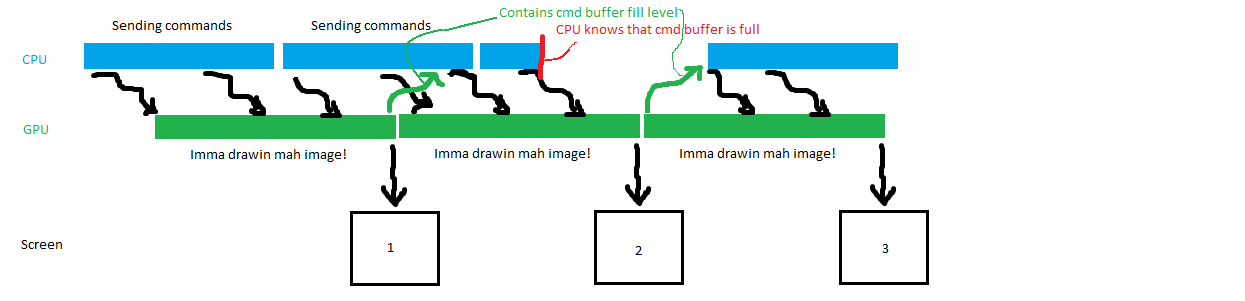
Wie man sieht, kann die GPU in der asynchronen Variante mehr Bilder pro Sekunde auf den Bildschirm spucken. Von komplexeren Dingen, wie dass mehrere Anwendungen sich ja die GPU teilen müssen, ganz zu schweigen. Und nun vierteilt mich, weil das hier eigentlich alles nur ein naiver Schuss ins Blaue war. Wo ist Lynxeye, wenn man ihn braucht? ;)
Das erklärt aber immer noch nicht, warum man 8 Sekunden (und nicht zwei Frames) auf die paar Texturen warten muss. Ich will man meine naive Sichtweise für eine GPU-bound Anwendung darlegen:http://msdn.microsoft.com/en-us/library/windows/desktop/bb205132.aspx hat geschrieben:It is best to think of a PC as a machine running as a parallel architecture with two main types of processors: one or more CPU's and one or more GPU's. As in any parallel architecture, the best performance is achieved when each processor is scheduled with enough tasks to prevent it from going idle and when the work of one processor is not waiting on the work of another.
The worst-case scenario for GPU/CPU parallelism is the need to force one processor to wait for the results of work done by another. Direct3D 10 tries to remove this cost by making the ID3D10Device::CopyResource and ID3D10Device::CopySubresourceRegion methods asynchronous; the copy has not necessarily executed by the time the method returns. The benefit of this is that the application does not pay the performance cost of actually copying the data until the CPU accesses the data, which is when Map is called. If the Map method is called after the data has actually been copied, no performance loss occurs. On the other hand, if the Map method is called before the data has been copied, then a pipeline stall will occur.
Asynchronous calls in Direct3D 10 (which are the vast majority of methods, and especially rendering calls) are stored in what is called a command buffer. This buffer is internal to the graphics driver and is used to batch calls to the underlying hardware so that the costly switch from user mode to kernel mode in Microsoft Windows occurs as rarely as possible.
The command buffer is flushed, thus causing a user/kernel mode switch, in one of four situations, which are as follows.
Of the four situations above, number four is the most critical to performance. If the application issues a ID3D10Device::CopyResource or ID3D10Device::CopySubresourceRegion call, this call is queued in the command buffer. If the application then tries to map the staging resource that was the target of the copy call before the command buffer has been flushed, a pipeline stall will occur because not only does the Copy method call need to execute, but all other buffered commands in the command buffer must execute as well. This will cause the GPU and CPU to synchronize because the CPU will be waiting to access the staging resource while the GPU is emptying the command buffer and finally filling the resource the CPU needs. Once the GPU finishes the copy, the CPU will begin accessing the staging resource, but during this time, the GPU will be sitting idle.
- Present is called.
- ID3D10Device::Flush is called.
- The command buffer is full; its size is dynamic and is controlled by the Operating System and the graphics driver.
- The CPU requires access to the results of a command waiting to execute in the command buffer.
Doing this frequently at runtime will severely degrade performance. For that reason, mapping of resources created with default usage should be done with care. The application needs to wait long enough for the command buffer to be emptied and thus have all of those commands finish executing before it tries to map the corresponding staging resource. How long should the application wait? At least two frames because this will enable parallelism between the CPU(s) and the GPU to be maximally leveraged. The way the GPU works is that while the application is processing frame N by submitting calls to the command buffer, the GPU is busy executing the calls from the previous frame, N-1.
So if an application wants to map a resource that originates in video memory and calls ID3D10Device::CopyResource or ID3D10Device::CopySubresourceRegion at frame N, this call will actually begin to execute at frame N+1, when the application is submitting calls for the next frame. The copy should be finished when the application is processing frame N+2.
Mit kompletter CPU-GPU-Synchronisierung:
Asynchron:
Wie man sieht, kann die GPU in der asynchronen Variante mehr Bilder pro Sekunde auf den Bildschirm spucken. Von komplexeren Dingen, wie dass mehrere Anwendungen sich ja die GPU teilen müssen, ganz zu schweigen. Und nun vierteilt mich, weil das hier eigentlich alles nur ein naiver Schuss ins Blaue war. Wo ist Lynxeye, wenn man ihn braucht? ;)
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
"Was spricht dagegen, CPU und GPU am Ende jedes Einzelbilds zu synchronisieren?"
=> Idealerweise will man fuer das naechste Bild den Command-Stream schon fertig haben, warum also die CPU blockieren wenn man nicht muss? Klassisches Pipelining-Problem...
Texturen speichern: Welches Format verwendest du im speziellen? Ein komprimiertes?
=> Idealerweise will man fuer das naechste Bild den Command-Stream schon fertig haben, warum also die CPU blockieren wenn man nicht muss? Klassisches Pipelining-Problem...
Texturen speichern: Welches Format verwendest du im speziellen? Ein komprimiertes?
-
Krishty
- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Aber die GPU fängt doch erst beim Present() an, ihre Anweisungen abzuarbeiten (begleitet davon, dass der Treiber erst dort die Abhängigkeitshierarchie auflöst um unnötige Anweisungen und Ressourcen zu überspringen).
eXile, auf deine Bilder bezogen bedeutet das, dass die synchrone Grafik noch weiter auseinandergezogen wird, weil CPU und GPU nie gleichzeitig arbeiten. Die asynchrone Grafik bleibt zwar so kompakt, allerdings rutschen die Pfeile mächtig weit nach hinten, weil die asynchrone Verarbeitung bedeutet, dass die GPU erst auf dein aktuelles Present() reagiert, nachdem sie die fünf Bilder abgearbeitet hat, die vorher im Anweisungspuffer eingereiht waren. Du hast also tatsächlich mehr Bilder pro Sekunde, aber auch eine höhere Latenz zwischen CPU und GPU und damit eine trägere Reaktion. Mir persönlich sind 30 Hz mit einer Latenz von 35 ms lieber als 85 Hz mit einer Latenz von 0–100, also im Schnitt 50 ms.
Mir sieht die ganze Chose danach aus, als sei sie darauf getrimmt, CPU und GPU maximal auszulasten um in Benchmarks mit möglichst viel Hz zu glänzen; aber dass die Hälfte dieser Auslastung umsonst ist und durch höhere Latenz bezahlt wird, scheint egal.
Jetzt erklärt mia bitte, was ich daran falsch sehe.
paint sk0llz ftw
eXile, auf deine Bilder bezogen bedeutet das, dass die synchrone Grafik noch weiter auseinandergezogen wird, weil CPU und GPU nie gleichzeitig arbeiten. Die asynchrone Grafik bleibt zwar so kompakt, allerdings rutschen die Pfeile mächtig weit nach hinten, weil die asynchrone Verarbeitung bedeutet, dass die GPU erst auf dein aktuelles Present() reagiert, nachdem sie die fünf Bilder abgearbeitet hat, die vorher im Anweisungspuffer eingereiht waren. Du hast also tatsächlich mehr Bilder pro Sekunde, aber auch eine höhere Latenz zwischen CPU und GPU und damit eine trägere Reaktion. Mir persönlich sind 30 Hz mit einer Latenz von 35 ms lieber als 85 Hz mit einer Latenz von 0–100, also im Schnitt 50 ms.
Du meinst, die GPU blockieren? Die CPU ist ja sowieso mit dem Schicken von Anweisungen beschäftigt, von denen am Ende die Hälfte ignoriert werden wird. Für die Latenz wäre es optimal, wenn die GPU sofort beim Eintrudeln der ersten Anweisung mit dem Zeichenvorgang begönne. Allerdings würde das wirksame Optimierungen unterdrücken, wie die Prüfung, ob es diese Anweisung überhaupt ins finale Monitorbild schafft.Jörg hat geschrieben:=> Idealerweise will man fuer das naechste Bild den Command-Stream schon fertig haben, warum also die CPU blockieren wenn man nicht muss? Klassisches Pipelining-Problem...
Mir sieht die ganze Chose danach aus, als sei sie darauf getrimmt, CPU und GPU maximal auszulasten um in Benchmarks mit möglichst viel Hz zu glänzen; aber dass die Hälfte dieser Auslastung umsonst ist und durch höhere Latenz bezahlt wird, scheint egal.
Jetzt erklärt mia bitte, was ich daran falsch sehe.
paint sk0llz ftw
- sy.png (4.1 KiB) 5595 mal betrachtet
-
Schrompf
- Moderator
- Beiträge: 5402
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas
- Wohnort: Dresden
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Das ist der Fehler, glaube ich. Der Treiber betreibt nach meinem Wissen dieses Auflösen der States und Abhängigkeiten bei jedem DrawCall, nicht pro Present().Krishty hat geschrieben:Aber die GPU fängt doch erst beim Present() an, ihre Anweisungen abzuarbeiten (begleitet davon, dass der Treiber erst dort die Abhängigkeitshierarchie auflöst um unnötige Anweisungen und Ressourcen zu überspringen).
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
-
Krishty
- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Wie soll das gehen? Die große Einsparung ist ja, Draw Calls zu ignorieren. Aber ob ein Draw Call Wirkung hat, weiß man nicht vor dem Present(). Mir persönlich gehen Draw Calls auch ein Bisschen zu schnell, als dass da voll ausgewertet werden würde.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Hatte es mit DDS und BMP probiert.Jörg hat geschrieben:Texturen speichern: Welches Format verwendest du im speziellen? Ein komprimiertes?
Das mausert sich ja hier zu einem übelst interessanten Thema! Wir müssten auf jeden Fall mal genau klären, wie es sich wirklich verhält. Denn das Problem mit den Frames verschlucken usw. ist ja richtig relevant. Da man jedes Frame ja unter dem Aspekt einer bestimmten Zeit-Variable zeichnen, würde sich Verzögerungen direkt als Ruckler äußern, auch wenn die Framerate an sich flüssig und konstant bleibt.
Ich habe mal den Effekt beobachtet, dass, wenn die Grafikkarte richtig ausgelastet ist, und man z.B. in eine bestimmte Richtung fliegt ( lineare Bewegung, nicht beschleunigt oder so ) sich die Bewegung vielleicht bis zu einer halben Sekunde noch nach loslassen der Taste weiter vollzieht. Also gefühlte 5 bis 10 Bilder... in Extremfällen.
-
Krishty
- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Anyone? Lynxeye und Jörg, gebt mich nicht auf!
-
dot

- Establishment
- Beiträge: 1752
- Registriert: 06.03.2004, 18:10
- Echter Name: Michael Kenzel
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Das ist alles nichtmehr so einfach. Ab Vista hat deine Anwendung keinen exklusiven Zugriff mehr auf die GPU (genau darum ist der ganze LostDevice Kram verschwunden). Das Betriebssystem hat nun auch einen GPU Scheduler, der den Zugriff auf die GPU Scheduled und virtualisiert den VRAM. Der Grafiktreiber besteht nun aus zwei Teilen, einem User Mode Driver (UMD) und einem Kernel Mode Driver (KMD). Über D3D redest du im Prinzip mit dem UMD. Der UMD baut den D3D-Calls entsprechend im Hintergrund einen fertigen Command Buffer für die GPU zusammen. Der GPU-Scheduler entscheidet, wann deine Anwendung die GPU bekommt und genau dann wird dein Command Buffer an den KMD übergeben, der diesen dann auf der GPU zur Ausführung bringt, wobei das OS dabei jederzeit preemten kann. Warten wird die CPU afaik nur wenn notwendig, also z.B. wenn sie der GPU davonläuft oder z.B. wenn du das Ergebnis von einem früheren Call zurücklesen willst etc.
-
Schrompf
- Moderator
- Beiträge: 5402
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas
- Wohnort: Dresden
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Es wäre mir neu, dass der Treiber ganze DrawCalls einsparen kann. Er darf doppelte State-Zuweisungen und sowas einsparen, aber die Programmlogik hinter dem Treiber ist doch reichlich primitiv. Alles jenseits doppelter States ist nach meinem Wissen Aufgabe der Engine.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
-
dot
- Establishment
- Beiträge: 1752
- Registriert: 06.03.2004, 18:10
- Echter Name: Michael Kenzel
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Die Logik in so einem Treiber ist alles andere als primitiv. Dass der Treiber evtl. DrawCalls zusammenfasst, hätt ich jetzt nicht zum ersten Mal gehört, wobei ich glaub, dass das nur z.B. bei OpenGL VertexArrays geht, wo die Daten sowieso erst zur GPU müssen. Denn wenn die DrawCalls auf verschiedene VertexBuffer referenzieren, wird das eher nicht gehen. Aber der Treiber tut weit mehr als nur "doppelte State Zuweisungen einsparen". Das macht afaik sogar schon die D3D-Runtime lange vor dem Treiber. Eine Stateänderung wird nicht einfach direkt zur GPU geschickt. Eine moderne GPU kann gar nicht einfach so einzelne States ändern. Viele "States" werden da evtl. direkt in den Shader kompiliert, weil sie in der Hardware gar nicht existieren, sodass der Treiber von jedem deiner Shader im Hintergrund verschiedenste Versionen warmhält. Andere States werden afaik z.B. erst mit bzw. unmittelbar vor einem DrawCall geschickt. Aber nicht einzeln, sondern in Form ganzer State-Blöcke für einzelne Pipeline Stages. Das ist auch der Grund warum State-Änderungen nichtmehr so pauschal ein Performancefaktor sind.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Unter bestimmten Umstaenden kann ein Treiber Drawcalls einsparen, bspw:
Draw Draw Draw Draw FULLSCREEN_CLEAR Draw Draw Present
Warum also GPU Zeit / Energie / Bandbreite verschwenden um die ersten 4 abzuarbeiten?
Oder ein anderen Beispiel: Ein Offscreen-Target wird freudig bemalt und doch niemals weiterverwendet, weil ein Occlusion-Query die Reflektion / Schatten / Was-Weiss-Ich im letzten Moment vor dem finalen Drawcall killt.
Und zu guter letzt: Vergesst nicht, dass es verschiedene Arten von Grafikhardware gibt: Immediate Mode GPUs und Deferred Rendering GPUs. Auch auf dem Desktop ;) Erstere koennten theoretische jeden Drawcall sofort abschicken, letztere wuerden arg leiden.
Draw Draw Draw Draw FULLSCREEN_CLEAR Draw Draw Present
Warum also GPU Zeit / Energie / Bandbreite verschwenden um die ersten 4 abzuarbeiten?
Oder ein anderen Beispiel: Ein Offscreen-Target wird freudig bemalt und doch niemals weiterverwendet, weil ein Occlusion-Query die Reflektion / Schatten / Was-Weiss-Ich im letzten Moment vor dem finalen Drawcall killt.
Und zu guter letzt: Vergesst nicht, dass es verschiedene Arten von Grafikhardware gibt: Immediate Mode GPUs und Deferred Rendering GPUs. Auch auf dem Desktop ;) Erstere koennten theoretische jeden Drawcall sofort abschicken, letztere wuerden arg leiden.
Schoen waere es, ja! Aber verkaufst Du ein Produkt in dem Du die Schuld auf andere schiebst? Alles was der Treiber irgendwie machen kann, macht er. Was meinst Du, warum es nach jedem grossen Spiel erstmal neue Treiber der Desktop-Groessen gibt? Lustige GUI's z.B. die schoen Szenegraph-maessig zeichnen scheren sich einen Mist um Vorsortierung, etc. Multi-Media-Plugins aasen in ihren "GPU-beschleunigten" Backends mit 300 Resource-Erzeugungen/-Zerstoerungen pro Frame. Leider muss das der Treiber abfangen, kannst ja schlecht sagen, die FPS sind so niedrig weil der Benchmark scheisse ist, nicht war ?;)Schrompf hat geschrieben:... aber die Programmlogik hinter dem Treiber ist doch reichlich primitiv. Alles jenseits doppelter States ist nach meinem Wissen Aufgabe der Engine.
-
Lynxeye

- Establishment
- Beiträge: 145
- Registriert: 27.02.2009, 16:50
- Echter Name: Lucas
- Wohnort: Hildesheim
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
So, debunking myths:
Und der Commandbuffer wird keinesfalls erst beim Present() gefüllt, das würde dem Treiber viel zu viele Cachemisses einbringen. Dazu gehören auch große Datenpakete wie die Vertexbuffer in einem DrawPrimitiveUP(), bei welchem die Daten sofort übernommen werden müssen, da der UP nur für den Aufruf des DrawCalls garantiert valide ist. Beim Present() darf dieser Pointer schon ins Nichts zeigen, womit diese Daten erst in einen Treiberpuffer umkopiert werden müssten, um dann wieder im Commandbuffer zu landen; auch keine gute Idee, nicht?
Der Treiber führt nur sehr simple Optimierungen auf dem Commandbuffer durch, wie beispielsweise die Entscheidung, ob Vertices direkt durch den Commandbuffer zu GPU geschickt werden, oder durch ein eigenes Vertexbufferobjekt.
Um optimale Auslastung zu garantieren würde es theoretisch reichen die CPU einen Frame vor der GPU laufen zu lassen, dann darf man allerdings keine Ressourcen von der GPU mappen um den aktuellen Commandstream zu erzeugen. In diesem Falle würde sonst die CPU stehen, bis die GPU die Ressource freigegeben hat. Der Commandbuffer hat außerdem eine relativ feste Größe, weshalb er auch vor einem Present() geflusht werden kann, oder nach einem Present() noch weitere Daten in den Commandbuffer gefüllt werden können. Unvollständige Commandbuffer sind durch die Host<->GPU Interaktion ein größeres Hindernis für die Performance als ein paar Vertices zu viel im Commandstream.
Nach jedem Bild zu synchronisieren würde dir einbringen, dass du in jedem Frame CPU-Zeit brauchst um den Commandbuffer zu füllen, in dem deine GPU Däumchen drehen würde. Keine gute Idee, oder?Krishty hat geschrieben:Was bringt eine asynchrone GPU eigentlich? Ich meine: Mir ist durchaus klar, dass es ungünstig wäre, die CPU zwischen Zeichenbefehlen auf die GPU warten zu lassen. Aber wtf soll es bringen, die GPU 100 ms hinterherzeichnen zu lassen?! Was spricht dagegen, CPU und GPU am Ende jedes Einzelbilds zu synchronisieren?
Und der Commandbuffer wird keinesfalls erst beim Present() gefüllt, das würde dem Treiber viel zu viele Cachemisses einbringen. Dazu gehören auch große Datenpakete wie die Vertexbuffer in einem DrawPrimitiveUP(), bei welchem die Daten sofort übernommen werden müssen, da der UP nur für den Aufruf des DrawCalls garantiert valide ist. Beim Present() darf dieser Pointer schon ins Nichts zeigen, womit diese Daten erst in einen Treiberpuffer umkopiert werden müssten, um dann wieder im Commandbuffer zu landen; auch keine gute Idee, nicht?
Der Treiber führt nur sehr simple Optimierungen auf dem Commandbuffer durch, wie beispielsweise die Entscheidung, ob Vertices direkt durch den Commandbuffer zu GPU geschickt werden, oder durch ein eigenes Vertexbufferobjekt.
Um optimale Auslastung zu garantieren würde es theoretisch reichen die CPU einen Frame vor der GPU laufen zu lassen, dann darf man allerdings keine Ressourcen von der GPU mappen um den aktuellen Commandstream zu erzeugen. In diesem Falle würde sonst die CPU stehen, bis die GPU die Ressource freigegeben hat. Der Commandbuffer hat außerdem eine relativ feste Größe, weshalb er auch vor einem Present() geflusht werden kann, oder nach einem Present() noch weitere Daten in den Commandbuffer gefüllt werden können. Unvollständige Commandbuffer sind durch die Host<->GPU Interaktion ein größeres Hindernis für die Performance als ein paar Vertices zu viel im Commandstream.
Sorry, das ist falsch. Selbst Fermi GPUs sind noch zum größten Teil in Hardware gegossenes OpenGL. Das heißt die gesamte GPU ist eine riesige Statemachine und einzelne States werden immer noch über einzelne Register geändert. Im Shaderheader stehen relativ wenige Informationen und der Shadercode unterscheidet nicht zwischen einzelnen States.dot hat geschrieben:Eine Stateänderung wird nicht einfach direkt zur GPU geschickt. Eine moderne GPU kann gar nicht einfach so einzelne States ändern. Viele "States" werden da evtl. direkt in den Shader kompiliert, weil sie in der Hardware gar nicht existieren, sodass der Treiber von jedem deiner Shader im Hintergrund verschiedenste Versionen warmhält
Halbrichtig. Natürlich wird nicht jede Stateänderung einzeln an die GPU geschickt. Die Änderungen werden als Registerwrites in den Commandbuffer geschrieben und wenn der Puffer voll ist von der GPU per DMA abgeholt und ausgeführt.dot hat geschrieben:Andere States werden afaik z.B. erst mit bzw. unmittelbar vor einem DrawCall geschickt. Aber nicht einzeln, sondern in Form ganzer State-Blöcke für einzelne Pipeline Stages. Das ist auch der Grund warum State-Änderungen nichtmehr so pauschal ein Performancefaktor sind.
Auch halb richtig. Allerdings allokiert das BS nur Channel auf der GPU. Die Virtualisierung des VRAM übernimmt der Treiber und auch das "Scheduling" hat der Treiber grob über. Contextswitches führt die GPU selbstständig ohne Interaktion des Hosts oder gar des BS aus.dot hat geschrieben:Ab Vista hat deine Anwendung keinen exklusiven Zugriff mehr auf die GPU (genau darum ist der ganze LostDevice Kram verschwunden). Das Betriebssystem hat nun auch einen GPU Scheduler, der den Zugriff auf die GPU Scheduled und virtualisiert den VRAM.
-
Krishty
- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Ich könnte mich ja in meinen Zielen vergriffen haben, aber bisher hatte ich es immer darauf angelegt, mein Ziel mit so wenig Hardware-Auslastung wie möglich zu erreichen ;) Dass die GPU ununterbrochen zu 100 % schuftet heißt doch noch lange nicht, dass man das Problem effizienter gelöst hat als jemand, der die GPU nur zu 80 % auslastet – auch unter dem Gesichtspunkt der Latenz, von der mir hier niemand was erzählen will :)Lynxeye hat geschrieben:Nach jedem Bild zu synchronisieren würde dir einbringen, dass du in jedem Frame CPU-Zeit brauchst um den Commandbuffer zu füllen, in dem deine GPU Däumchen drehen würde. Keine gute Idee, oder?
Im Übrigen wäre das doch die Gelegenheit für den Scheduler, den anderen Prozessen Rechenzeit zuzuschreiben, anstatt mich zu unterbrechen, während ich sie dringend brauche. Dass heute jeder Browser GPU-beschleunigt arbeitet, hat bei mir nur bewirkt, dass Aero aus ist, weil ich sonst mit meinen Frame-Zeiten absolut auf keinen glatten Zweig mehr käme. Zusammenhängender Leerlauf an einer mehr oder weniger frei wählbaren Stelle wäre mir weitaus lieber als eine Unterbrechung mitten im Present(), die mich die nächste vertikale Synchronisation verpassen lässt, weil Flash im Hintergrund einen neuen Werbebanner anzeigen muss.
Ich hätte schwören können, dass zumindest mein AMD-Treiber eine vollständige Optimierung des Abhängigkeitsbaums durchführt – mühsam erzeugte und befüllte Ressourcen haben absolut keine GPU-Zeit verbraucht, falls ich beim finalen Draw-Call versehentlich eine Textur falsch gesetzt und sie deshalb nicht angezeigt hatte. Aber okay.Lynxeye hat geschrieben:Und der Commandbuffer wird keinesfalls erst beim Present() gefüllt, das würde dem Treiber viel zu viele Cachemisses einbringen. Dazu gehören auch große Datenpakete wie die Vertexbuffer in einem DrawPrimitiveUP(), bei welchem die Daten sofort übernommen werden müssen, da der UP nur für den Aufruf des DrawCalls garantiert valide ist. Beim Present() darf dieser Pointer schon ins Nichts zeigen, womit diese Daten erst in einen Treiberpuffer umkopiert werden müssten, um dann wieder im Commandbuffer zu landen; auch keine gute Idee, nicht?
Okay; das rückt es für mich gerade. Ich rufe übrigens Flush() auf, bevor die CPU zur nicht-Rendering-Arbeit übergeht. (Rendering macht so grob ein Hundertstel meiner Frame-Zeit aus; die CPU-Auslastung ist eh immer im einstelligen Bereich.) Legit? Das Present() dürfte dann ja minimal Zeit fressen, weil die GPU schon zu arbeiten angefangen hat; und bis zum nächsten Flush ist dann ungefähr ein hundertstel einer Frame-Dauer vergangen …Lynxeye hat geschrieben:Um optimale Auslastung zu garantieren würde es theoretisch reichen die CPU einen Frame vor der GPU laufen zu lassen, dann darf man allerdings keine Ressourcen von der GPU mappen um den aktuellen Commandstream zu erzeugen. In diesem Falle würde sonst die CPU stehen, bis die GPU die Ressource freigegeben hat. Der Commandbuffer hat außerdem eine relativ feste Größe, weshalb er auch vor einem Present() geflusht werden kann, oder nach einem Present() noch weitere Daten in den Commandbuffer gefüllt werden können. Unvollständige Commandbuffer sind durch die Host<->GPU Interaktion ein größeres Hindernis für die Performance als ein paar Vertices zu viel im Commandstream.
Namen! :PJörg hat geschrieben:Und zu guter letzt: Vergesst nicht, dass es verschiedene Arten von Grafikhardware gibt: Immediate Mode GPUs und Deferred Rendering GPUs. Auch auf dem Desktop ;) Erstere koennten theoretische jeden Drawcall sofort abschicken, letztere wuerden arg leiden.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Ich habe echt keine Ahnung. Aber eine Erfahrung möchte ich doch mal anführen, was eventuell doch auf eine Form von Zusammenfassung schließen lässt.
Damals hatte ich mal folgende Szene:
Zu sehen sind etwa 12.000 Schokotafeln einer bekannten Marke. Das ganze wurde am Anfang ohne Instanzing gezeichnet. Jede Tafel besteht aus zwei Objekte... das eine Objekt ist das Mittelstück und variiert in seiner Textur, das zweite sind außen die beiden Goldstreifen.
Im Nvidia PerfHUD konnte man nun schön sehen, wie abwechselnd immer das erste und das zweite Objekt gezeichnet wurden. Da kann man ja den Frame im Einzelschritt betrachten. Nachdem ich das ganze dann nach Materialien sortiert hatte und auch keine Statechanges mehr gemacht wurden, war es im Frame Debugger allerdings so, das nun hunderte Objekte immer in einem Schritt gezeichnet wurden. Das war extrem schnell und ich hatte mich gewundert. Wobei ich mit richtigem Instanzing dann hinterher die Framerate nochmal verdoppeln konnte.
Damals hatte ich mal folgende Szene:
Im Nvidia PerfHUD konnte man nun schön sehen, wie abwechselnd immer das erste und das zweite Objekt gezeichnet wurden. Da kann man ja den Frame im Einzelschritt betrachten. Nachdem ich das ganze dann nach Materialien sortiert hatte und auch keine Statechanges mehr gemacht wurden, war es im Frame Debugger allerdings so, das nun hunderte Objekte immer in einem Schritt gezeichnet wurden. Das war extrem schnell und ich hatte mich gewundert. Wobei ich mit richtigem Instanzing dann hinterher die Framerate nochmal verdoppeln konnte.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Namen:Intel GMA500 und Abkoemmlinge...leise lizensiert von Imagination (SGX Serie).
Da Du Flush erwaehnst: Das beisst sich natuerlich mit vollstaendiger Abhaengigsanalyse, und mehr als 1x pro Frame angewendet ist es nicht vorteilhaft fuer deferred GPUs, waehrend immediate Architekturen das leichter schlucken.
Und mit nur 1 Frame Vorlauf wuerde ich auch nicht rechnen wollen, Triple-Buffering ist durchaus nuetzlich, wenn man nicht staendig die 60/75/120 Hz schafft, Tearing vermeiden will und dennoch eine gute Auslastung haben moechte.
Da Du Flush erwaehnst: Das beisst sich natuerlich mit vollstaendiger Abhaengigsanalyse, und mehr als 1x pro Frame angewendet ist es nicht vorteilhaft fuer deferred GPUs, waehrend immediate Architekturen das leichter schlucken.
Und mit nur 1 Frame Vorlauf wuerde ich auch nicht rechnen wollen, Triple-Buffering ist durchaus nuetzlich, wenn man nicht staendig die 60/75/120 Hz schafft, Tearing vermeiden will und dennoch eine gute Auslastung haben moechte.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
PS Namen: Wird die 360-GPU in FullHD-4xAA nicht auch zum Deferred Renderer? ;)
-
Krishty
- Establishment
- Beiträge: 8422
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Ja; ich meinte auch, dass zu diesem Zeitpunkt mein Frame schon mehr oder minder vollständig der Runtime beschrieben wurde und danach nur noch in einiger Ferne das Present() kommen wird.Jörg hat geschrieben:Da Du Flush erwaehnst: Das beisst sich natuerlich mit vollstaendiger Abhaengigsanalyse, und mehr als 1x pro Frame angewendet ist es nicht vorteilhaft fuer deferred GPUs, waehrend immediate Architekturen das leichter schlucken.
Ugh, stimmt. Das war mir fast schon in Vergessenheit geraten …Jörg hat geschrieben:Und mit nur 1 Frame Vorlauf wuerde ich auch nicht rechnen wollen, Triple-Buffering ist durchaus nuetzlich, wenn man nicht staendig die 60/75/120 Hz schafft, Tearing vermeiden will und dennoch eine gute Auslastung haben moechte.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Was hat es eigentlich mit DXGI_SWAP_EFFECT_FLIP_SEQUENTIAL auf sich? Ist das das magische Flag, damit der Jitter der Framezeiten mit aktiviertem DWM nicht verrückt spielt?Krishty hat geschrieben:Ugh, stimmt. Das war mir fast schon in Vergessenheit geraten …Jörg hat geschrieben:Und mit nur 1 Frame Vorlauf wuerde ich auch nicht rechnen wollen, Triple-Buffering ist durchaus nuetzlich, wenn man nicht staendig die 60/75/120 Hz schafft, Tearing vermeiden will und dennoch eine gute Auslastung haben moechte.
-
Lynxeye
- Establishment
- Beiträge: 145
- Registriert: 27.02.2009, 16:50
- Echter Name: Lucas
- Wohnort: Hildesheim
- Kontaktdaten:
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Deine Ziele sind aber doch bitte die konstanten 60Hz. Dazu darfst du die GPU aber nicht warten lassen, während du den Commandbuffer für den nächsten Frame füllst, falls deine GPU doch limitiert und zu 100% ausgelastet werden muss.Krishty hat geschrieben:Ich könnte mich ja in meinen Zielen vergriffen haben, aber bisher hatte ich es immer darauf angelegt, mein Ziel mit so wenig Hardware-Auslastung wie möglich zu erreichen ;) Dass die GPU ununterbrochen zu 100 % schuftet heißt doch noch lange nicht, dass man das Problem effizienter gelöst hat als jemand, der die GPU nur zu 80 % auslastet – auch unter dem Gesichtspunkt der Latenz, von der mir hier niemand was erzählen will :)Lynxeye hat geschrieben:Nach jedem Bild zu synchronisieren würde dir einbringen, dass du in jedem Frame CPU-Zeit brauchst um den Commandbuffer zu füllen, in dem deine GPU Däumchen drehen würde. Keine gute Idee, oder?
Da du deiner Aussage nach jedoch schon Async renderst und danach flushst, dürfte dir das Problem schon klar sein. Und natürlich ist dein Vorgehen im Sinne der Latenz gut, aber ich dachte auch das wäre dir klar. Das viele Spiele die GPU so weit hinterher rennen liegt einfach an Leuten, welche die Uploadpfade zur GPU nicht verstehen und deshalb ihr Framedaten erst direkt vor dem Frame hochladen; wenn die GPU dann hinterher rennt, ist dann von Vorteil, da die Daten dann auf jeden Fall bereit stehen.
Wie vorher schon gesagt: es gibt keinen GPU Scheduler. Die Applikationen und das BS allokieren nur Channel auf der GPU, welche die Contextswitches automatisch ausführt, vorzugsweise wenn der mit dem Channel verbundene Commandbuffer leergelaufen ist. Die Channel werden bei NVidia GPUs per Hardwaresemaphoren synchronisiert. Der Compositor (Aero) ist auch nur ein solcher Channel, welcher dann in einem Rutsch die ganzen Present() Anfragen umsetzt. Wenn nun der Browser oder Flash GPU Channel noch einen vollen Commandbuffer hat, verhindert dieser natürlich den GPU Contextswitch auf den Aero Channel und versaut dir damit dein Presentinterval. Das heißt: es ist egal, wie viel freie Zeit deine GPU hat, solange Flash es schafft mehr Arbeit für die GPU zu generieren als freie Zeit da ist, wird deine Framezeit am Arsch sein, da der Compositorchannel nicht zu festen Zeiten geschedult wird, sondern wenn die anderen Channel durch sind.Krishty hat geschrieben:Im Übrigen wäre das doch die Gelegenheit für den Scheduler, den anderen Prozessen Rechenzeit zuzuschreiben, anstatt mich zu unterbrechen, während ich sie dringend brauche. Dass heute jeder Browser GPU-beschleunigt arbeitet, hat bei mir nur bewirkt, dass Aero aus ist, weil ich sonst mit meinen Frame-Zeiten absolut auf keinen glatten Zweig mehr käme. Zusammenhängender Leerlauf an einer mehr oder weniger frei wählbaren Stelle wäre mir weitaus lieber als eine Unterbrechung mitten im Present(), die mich die nächste vertikale Synchronisation verpassen lässt, weil Flash im Hintergrund einen neuen Werbebanner anzeigen muss.
Re: [DX9] D3DXSaveTextureToFile(InMemory) langsam
Aus diesem Grund moechte Microsoft schon seit einiger Zeit GPUs, die "ordentlich" Kontext-Umschaltbar sind...aber die "Grossen" scheinen sich damit etwas Zeit zu lassen.